- Published on
Các thuật toán tìm kiếm phổ biến
- Authors
- Name
- Khiem Le
- @khiemledev




Vì sao cần có thuật toán tìm kiếm?
Trong thực tế, có rất nhiều bài toán, nhưng hầu như tất cả chúng đều quy về một bài toán duy nhất, đó chính là bài toán tìm kiếm. Ví dụ như khi bạn giải một bài toán, bạn có làm cách nào đi nữa thì mục đích cuối cùng của bạn chính là đi tìm lời giải của bài toán. Hay khi bạn thực hiện sắp xếp, lọc các phần tử của danh sách, mục đích của bạn cũng là tìm kiếm những phần tử thỏa mãn yêu cầu.
Từ những nhu cầu thực tế đó, bài toán tìm kiếm dẫn đến chúng ta phải tạo ra thuật toán tìm kiếm để giải quyết nó. Vậy thì thuật toán tìm kiếm là gì? Thuật toán tìm kiếm (searching algorithm) là thuật toán giúp ta tìm ra trong một tập dữ liệu đã cho một hoặc nhiều phần tử thỏa mãn yêu cầu tìm kiếm.
Tùy theo cấu trúc dữ liệu mà chúng ta sẽ có những thuật toán tìm kiếm khác nhau phù hợp cho mỗi cấu trúc đó. Do đó, chúng ta không nên học thuộc lòng thuật toán tìm kiếm trên một tập dữ liệu, một cấu trúc dữ liệu trong một ngôn ngữ cụ thể nào đó. Hãy học ý tưởng của thuật toán và áp dụng nó linh hoạt cho các cấu trúc dữ liệu khác nhau trong các ngôn ngữ lập trình khác nhau.
Trong bài này, mình sẽ dùng C++ để minh họa cho các thuật toán tìm kiếm, các bạn có thể áp dụng nó cho bất kỳ ngôn ngữ lập trình nào mà các bạn thích như Java hay Python...
Các thuật toán tìm kiếm
Trong bài viết này, mình sẽ giới thiệu đến các bạn 3 thuật toán tìm kiếm phổ biến nhất: tìm kiếm tuyến tính, tìm kiếm nhị phân và tìm kiếm nội suy. Giờ hãy bắt đầu tìm hiểu về các thuật toán tìm kiếm này nhé!
Tìm kiếm tuyến tính
Tìm kiếm tuyến tính (linear search) hay tìm kiếm tuần tự (sequential search) là thuật toán tìm kiếm bằng cách duyệt qua tất cả các phần tử của danh sách cho đến khi gặp phần tử cần tìm hoặc là đã hết danh sách. Do cách tìm kiếm duyệt từ đầu đến cuối này, độ phức tạp thời gian của thuật toán này sẽ là O(n).
Chúng ta có một mảng A có n phần tử bắt đầu từ vị trí 0. Để tìm kiếm phần tử x trong mảng A này, ta làm như sau:
- Gán i = 0.
- So sánh giá trị của A[i] và x:
- Nếu A[i] == x thì dừng và trả về giá trị của i (vị trí của x trong mảng A).
- Nếu A[i] != x thì sang bước 3.
- Gán i = i + 1:
- Nếu i == n (tức hết mảng) thì dừng lại và trả kết quả là -1 (không tìm thấy x).
- Nếu i < n thì quay lại bước 2.

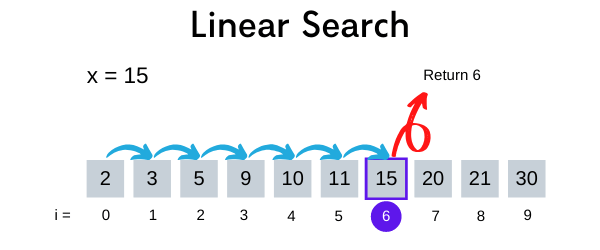
Tìm kiếm tuyến tính
Dựa trên những thao tác trên, chúng ta có thể viết lại code trong C++ như sau:
int LinearSearch(int A[], int n, int x)
{
int i = 0;
while (i < n && A[i] != x)
i++;
if (i == n)
return -1; // không tìm thấy x
return i; // tìm thấy x, trả về vị trí của x trong mảng a
}
Thông thường, các bạn hay sử dụng for cho nó đơn giản như sau:
int LinearSearch(int A[], int n, int x)
{
for (int i = 0; i < n; i++)
if (A[i] == x)
return i;
return -1; // duyệt hết mảng, không tìm thấy x
}
Chúng ta có thể cải tiến nó một chút bằng phương pháp đặt lính canh như sau: gán A[n] = x, trong lúc kiểm tra không cần kiểm tra i < n nữa bởi vì nếu chạy đến cuối cùng thế nào cũng gặp x chính là "lính" chúng ta vừa đặt. Vậy thuật toán trở thành:
int LinearSearch(int A[], int n, int x)
{
int i = 0;
A[n] = x;
while (A[i] != x)
i++;
if (i == n)
return -1;
return i;
}
Các bạn có thể xem video sau để hiểu rõ hơn:
Youtube: Thuật toán tìm kiếm tuyến tính | Khiêm Lê
Tìm kiếm nhị phân
Tìm kiếm nhị phân (binary search) hay còn một số tên gọi khác nữa như tìm kiếm nửa khoảng (half-interval search), tìm kiếm logarit (logarithmic search), chặt nhị phân (binary chop) là thuật toán tìm kiếm dựa trên việc chia đôi khoảng đang xét sau mỗi lần lặp, sau đó xét tiếp trong nửa khoảng có khả năng chứa giá trị cần tìm, cứ như vậy cho đến khi không chia đôi khoảng được nữa. Thuật toán tìm kiếm nhị phân chỉ áp dụng được cho danh sách đã có thứ tự hay đã được sắp xếp.
Ví dụ như bạn có một dãy số tăng từ 1 đến 100, yêu cầu bạn tìm số 30. Bạn xem phần tử chính giữa của dãy số thì thấy là số 50, vậy thì bạn biết chắc là 30 chỉ có thể nằm trong khoảng dưới 50 thôi, vậy thì giới hạn tìm kiếm được thu hẹp lại một nửa. Ví dụ như tìm số 70 chẳng hạn thì 50 lại nhỏ hơn 70, do đó ta biết chắc 70 chỉ có thể nằm trong khoảng từ 51 đến 100 thôi. Cứ tiếp tục như thế cho đến khi tìm gặp hoặc không thể chia đôi khoảng nữa.
Do cách tìm kiếm chia đôi khoảng này, sau mỗi lần lặp, khoảng đang xét lại được chia đôi, và tiếp tục khoảng tiếp lại chia đôi khoảng đã được chia trước đó. Do đó, độ phức tạp thời gian của thuật toán này sẽ là O(log(n)), tốt hơn rất rất nhiều so với tìm kiếm tuyến tính.
Cho một mảng A có n phần tử bắt đầu từ vị trí 0, mảng A được sắp xếp tăng dần (lưu ý là thứ tự tăng dần, đối với giảm dần chúng ta sẽ có cách cài đặt khác một chút sẽ được trình bày bên dưới). Để tìm phần tử có giá trị x trong mảng A chúng ta sẽ cài đặt thuật toán tìm kiếm nhị phân như sau:
- Gán
left = 0,right = n - 1. - Gán
mid = (left + right) / 2(lấy phần nguyên, đây là phần tử chính giữa của khoảng hiện tại)- Nếu như A[mid] == x:
- Dừng lại và trả về giá trị của mid (chính là vị trí của x trong mảng A).
- Nếu như A[mid] > x (có thể x nằm trong nửa khoảng trước):
- right = mid - 1 // giới hạn khoảng tìm kiếm lại là nửa khoảng trước
- Nếu như A[mid] < x (có thể x nằm trong nửa khoảng sau):
- left = mid + 1 // giới hạn khoảng tìm kiếm lại là nửa khoảng sau
- Nếu như A[mid] == x:
- Nếu
left <= right:- Đúng thì quay lại bước 2 (còn chia đôi được).
- Sai thì dừng và trả về kết quả -1 (không tìm thấy x)

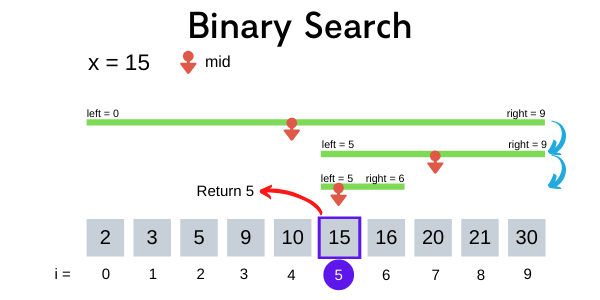
Tìm kiếm nhị phân
Thuật toán đã có, giờ hãy xem cài đặt nó trong C++ như thế nào nha:
int BinarySearch(int A[], int n, int x)
{
int left = 0;
int right = n - 1;
int mid;
while (left <= right)
{
mid = (left + right) / 2;
if (A[mid] == x)
return mid; // tìm thấy x, trả về mid là vị trí của x trong mảng A
if (A[mid] > x)
right = mid - 1; // Giới hạn khoảng tìm kiếm lại là nửa khoảng trước
else if (A[mid] < x)
left = mid + 1; // Giới hạn khoảng tìm kiếm lại là nửa khoảng sau
}
return -1; // không tìm thấy x
}
Đối với mảng được sắp xếp giảm, các bạn chỉ cần thay đổi chỗ so sánh A[mid] và x như sau:
- A[mid] < x:
- right = mid - 1
- A[mid] > x:
- left = mid + 1
Video minh họa ý tưởng thuật toán:
Youtube: Thuật toán tìm kiếm nhị phân | Khiêm Lê
Tìm kiếm nội suy
Tìm kiếm nội suy (interpolation search) là một thuật toán cải tiến từ thuật toán tìm kiếm nhị phân. Thay vì xác định điểm chính giữa của danh sách, thuật toán tìm kiếm nội suy xác định điểm gần với vị trí của phần tử cần tìm, do đó tối ưu được thời gian hơn so với thuật toán tìm kiếm nhị phân. Độ phức tạp thời gian cũng vì thế mà tốt hơn là O(log(log(n))).
Tuy nhiên, thuật toán tìm kiếm nhị phân luôn ổn định với độ phức tạp thời gian là O(log(n)), thuật toán tìm kiếm nội suy lại không như vậy. Trong những trường hợp xấu nhất như dãy tăng/giảm phân bố không đều, thuật toán tìm kiếm này đạt độ phức tạp là O(n), không khác gì dùng thuật toán tìm kiếm tuyến tính cả. Do đó, bạn nên sử dụng thuật toán tìm kiếm nhị phân để đảm bảo được độ phức tạp O(log(n)).
Vẫn là mảng A, vẫn n phần tử bắt đầu từ 0 và tăng dần. Tìm x trong mảng này dùng thuật toán tìm kiếm nội suy như sau:
- Gán
left = 0,right = n - 1. - Gán mid = left + (right - left) * (x - a[left]) / (a[right] - a[left]):
- Nếu như A[mid] == x:
- Dừng lại và trả về giá trị của mid.
- Nếu như A[mid] > x:
- right = mid - 1
- Nếu như A[mid] < x:
- left = mid + 1
- Nếu như A[mid] == x:
- Nếu
left <= rightvà x >= A[left] và x <= A[right] (x còn nằm trong đoạn [A[left]; A[right]]):- Đúng thì quay lại bước 2.
- Sai thì dừng và trả về kết quả -1 (không tìm thấy x)
Và tương tự với mảng giảm dần, bạn chỉ cần sửa lại:
- A[mid] < x:
- right = mid - 1
- A[mid] > x:
- left = mid + 1
Giờ hãy cùng xem cài đặt thuật toán tìm kiếm nội suy trong C++ với mảng tăng nha:
int InterpolationSearch(int A[], int n, int x)
{
int left = 0;
int right = n - 1;
int mid;
while (left <= right && x >= A[left] && x <= A[right])
{
mid = left + (right - left) * (x - A[left]) / (A[right] - A[left]);
if (A[mid] == x)
return mid;
if (A[mid] > x)
right = mid - 1;
else if (A[mid] < x)
left = mid + 1;
}
return -1; // Không tìm thấy x
}
Lưu ý: khi sử dụng thuật toán tìm kiếm nhị phân hoặc nội suy, nếu như mảng chưa được sắp xếp, nên sử dụng kèm với các thuật toán sắp xếp có hiệu suất cao như Quick Sort hay Merge Sort để sắp xếp nhằm tối ưu hóa thuật toán. Nếu tìm kiếm nhanh mà sắp xếp chậm cũng không có ý nghĩa gì đối với tập dữ liệu lớn.
Tổng kết
Vậy là qua bài viết này, mình đã giới thiệu đến các bạn 3 thuật toán tìm kiếm phổ biến nhất mà các lập trình viên nên biết. Trong hầu hết các bài tập, các bạn sẽ cần dùng đến các thuật toán tìm kiếm này, đừng quên luyện tập thật nhiều để thành thục các thao tác trên các cấu trúc dữ liệu khác nhau nha.
Nếu như các bạn thấy hay, đừng quên chia sẻ cho bạn bè cùng biết nha. Bạn cũng có thể để lại bình luận bên dưới bài viết nếu có bất kỳ thắc mắc hoặc góp ý nào. Cảm ơn các bạn đã theo dõi bài viết!